This website uses cookies. By clicking Accept, you consent to the use of cookies. Click Here to learn more about how we use cookies.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
NetWitness Discussions
- NetWitness Community
- Discussions
- How to: Clean all the data from db table for Automatic Monitoring (BETA)10.6 & 11
-
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to: Clean all the data from db table for Automatic Monitoring (BETA)10.6 & 11
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
2018-02-21 05:15 AM
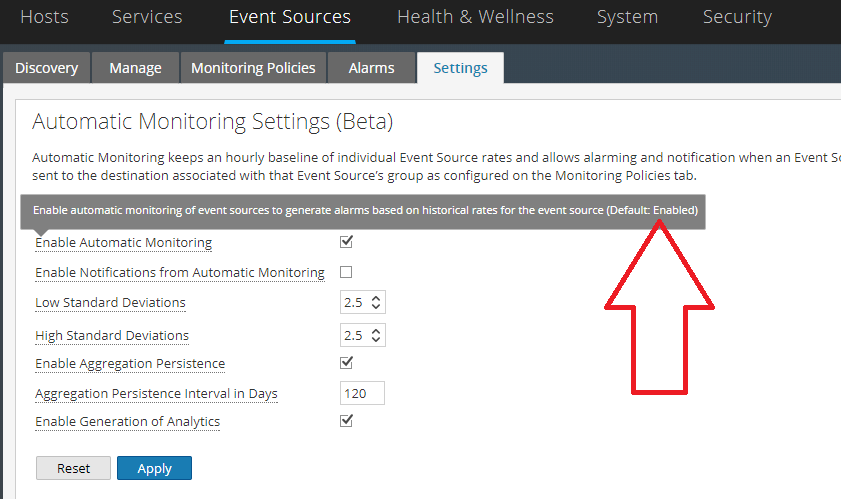
The purpose of this article is to alert other customers of this hidden BETA feature that engineering think that is disabled by default when it's not.
There is a bug open with RSA since 2016 but based on the evidence it doesn't seem that they want to fix it.
This feature completely made rabbitmq, IM and SMS to collapse in 10.6 and Support were investigating for more than a month to figure out what was the problem.
Eventually RSA CE asked us to drop the contents of 3 tables which accounted for 18GB of uncompressed data.
esmbaselinedata
esmaggregatedata
esmbaselineanalytics
Engineering initially thought that is was us (the customer) enabling it, before I provided plenty of screenshots showing the opposite. Then they made this statement:
"ESM baseline analytics related collections seem to be taking good amount of space in memory. So the automatic monitoring (its in beta) is disabled in many other environments."
To my surprise, I see that a BETA feature with its tables not maintained, could eventually affect rabbitmq,SMS and IM (even though ESM is not a separate service) as it is still enabled by default in v11. Not impressed.
If you face similar problems with services falling apart without explanation, check if you have this "very well tested feature" enabled by default.
You can quickly check the size of esm db, and it should be a few hundred MBs, even though there is no mechanism in place to purge old data so I can't think of how you would have a few MBs if this was enabled.
To check:
On SA server:
mongo
show dbs
Then check the size of ESM
To perform the cleanup:
On SA server:
service puppet stop
service rsa-sms stop
mongo esm
On the mongo prompt:
db.esmbaselinedata.drop();
db.esmaggregatedata.drop();
db.esmbaselineanalytics.drop();
exit
service rsa-sms start
service puppet start
2 REPLIES 2
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
2018-03-08 10:02 AM
If you are experiencing this issue of a very large ESM database causing issues with your UI and want to clear it out here is the official RSA knowledge base article for dealing with the database. https://community.rsa.com/docs/DOC-86315
When working with the internal databases for Netwitness please look for official ways (Knowledge Base Articles and/or official RSA responses) of dealing with those issues before utilizing suggestions on the forums as the suggestions may not be fully aware of all aspects related to those databases.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
2018-03-08 11:20 AM
I agree with your first points, however RSA hasn't done enough to help prevent or mitigate the situation.
The problem has been around with a Jira since 2016 so hardly any excuse would be justifiable from RSA's documentation view.
The attached article was created 2 days after I created mine and after spending months with Support.
Here is some generic feedback :
If RSA were concerned about customers making (or using) unofficial How to's they could have:
a) Fixed the problem (disabling BETA features by default)
b) Inform customers that RSA haven't thoroughly tested this and hence it is still in BETA, but enabled.
c) If fixing was not possible, clearly include documentation in upgrade notes and explain the potential risk vs reward of having this feature enabled. Then customers can make a calculated decision.
d) Making an official KB during the last 2 year period that this issue has been affecting customers.
Feedback about the article:
-It does not specify that 10.6.2, 10.6.3, 10.6.4 (not sure about 10.6.5 but I would bet) and 11 are also affected which is not true.
-The claim that this only happens in large deployments is also false.
We only have one half maxed log decoder but haven't been re-imaging every few months so that everything can get purged.
With that said, RSA need to keep in mind that for things that they haven't designed a purging mechanism, even small deployments are equally affected.

{kind=link}
{kind=link}